Restauração de alta disponibilidade no cluster do gerenciador de elementos Ultra-M - vEPC
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve as etapas necessárias para restaurar a alta disponibilidade (HA) no cluster do Element Manager (EM) de uma configuração do Ultra-M que hospeda as VNFs (Virtual Network Functions) do StarOS.
Informações de Apoio
O Ultra-M é uma solução de núcleo de pacotes móveis virtualizados, pré-embalada e validada, projetada para simplificar a implantação de VNFs. A solução Ultra-M consiste nos tipos de máquina virtual (VM) mencionados:
- TI automática
- Implantação automática
- Ultra Automation Services (UAS)
- Gerenciador de Elementos (EM)
- Controlador de serviços elásticos (ESC)
- Função de Controle (CF)
- Função da sessão (SF)
A arquitetura de alto nível da Ultra-M e os componentes envolvidos estão descritos nesta imagem:
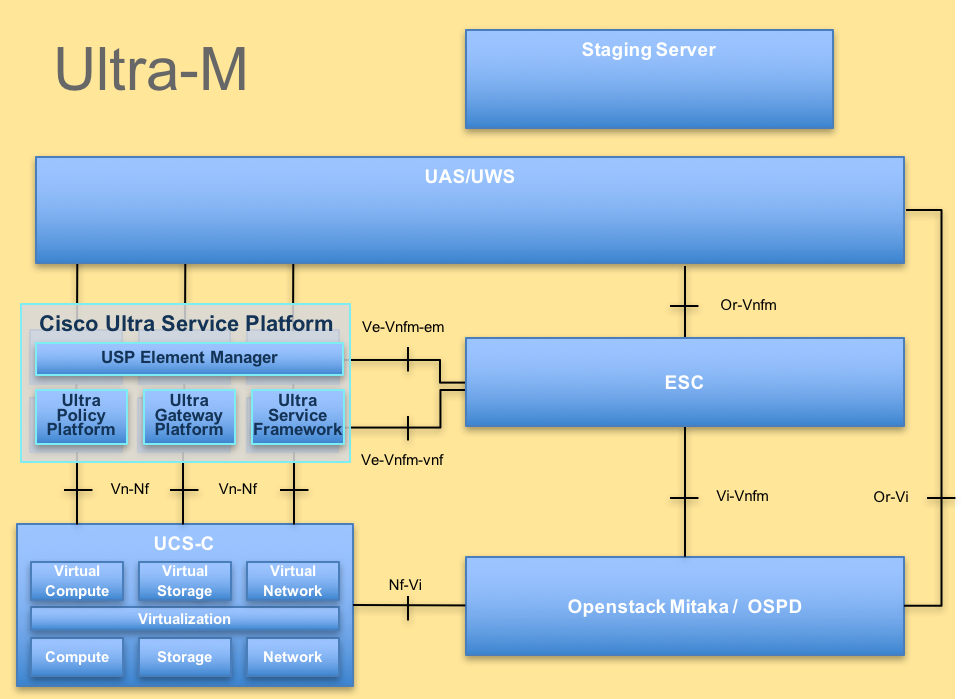 Arquitetura UltraM
Arquitetura UltraM
Este documento destina-se ao pessoal da Cisco que conhece a plataforma Ultra-M da Cisco.
Note: A versão Ultra M 5.1.x é considerada para definir os procedimentos neste documento.
Abreviaturas
| HA | Alta Disponibilidade |
| VNF | Função de rede virtual |
| CF | Função de controle |
| SF | Função de serviço |
| ESC | Controlador de serviço elástico |
| MOP | Método de Procedimento |
| OSD | Discos de Armazenamento de Objeto |
| HDD | Unidade de disco rígido |
| SSD | Unidade de estado sólido |
| VIM | Virtual Infrastructure Manager |
| VM | Máquina virtual |
| EM | Gestor de Elementos |
| UAS | Ultra Automation Services |
| UUID | Identificador de ID universal exclusivo |
Fluxo de trabalho do MoP
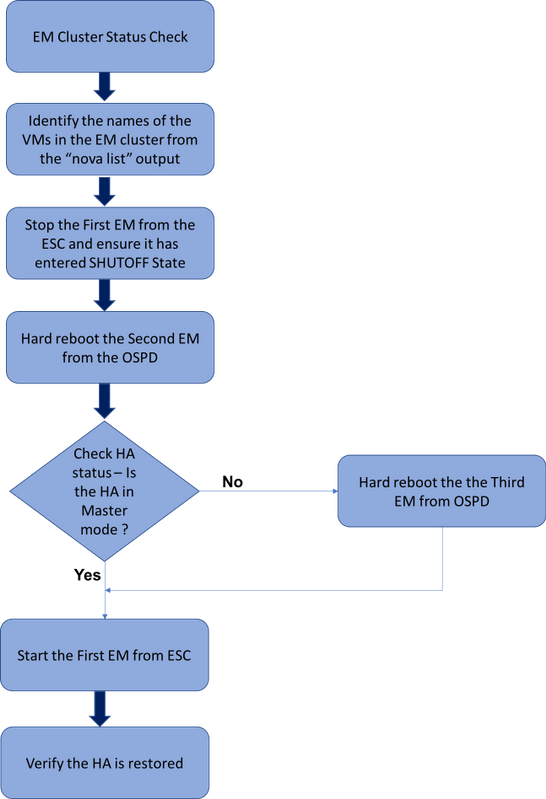 Fluxo de trabalho de alto nível do procedimento de restauração do HA da EM
Fluxo de trabalho de alto nível do procedimento de restauração do HA da EM
Verificar status do cluster
Faça login no EM ativo e verifique o status do HA. Pode haver dois cenários:
1. O modo HA é nenhum:
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode none
admin@scm# show ems
%no entries found%
2. O cluster EM tem apenas um nó (o cluster EM consiste em 3 VMs):
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
----------------------
2 up down down
Em ambos os casos, o estado HA pode ser restaurado pelas etapas mencionadas na próxima seção.
Procedimento de restauração HA
Identifique os nomes de VMs que fazem parte do cluster na lista nova. Haverá três VMs que fazem parte de um cluster EM.
[stack@director ~]$ nova list | grep vnfd1
| e75ae5ee-2236-4ffd-a0d4-054ec246d506 | vnfd1-deployment_c1_0_13d5f181-0bd3-43e4-be2d-ada02636d870 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.22; DI-INTERNAL2=192.168.2.17; DI-INTERNAL1=192.168.1.14; tmo-autovnf2-uas-management=172.18.181.23 |
| 33c779d2-e271-47af-8ad5-6a982c79ba62 | vnfd1-deployment_c4_0_9dd6e15b-8f72-43e7-94c0-924191d99555 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.13; DI-INTERNAL2=192.168.2.14; DI-INTERNAL1=192.168.1.4; tmo-autovnf2-uas-management=172.18.181.21 |
| 65344d53-de09-4b0b-89a6-85d5cfdb3a55 | vnfd1-deployment_s2_0_b2cbf15a-3107-45c7-8edf-1afc5b787132 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.4, 192.168.10.9; SERVICE-NETWORK2=192.168.20.17, 192.168.20.6; tmo-autovnf2-uas-orchestration=172.18.180.12; DI-INTERNAL2=192.168.2.6; DI-INTERNAL1=192.168.1.12 |
| e1a6762d-4e84-4a86-a1b1-84772b3368dc | vnfd1-deployment_s3_0_882cf1ed-fe7a-47a7-b833-dd3e284b3038 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.22, 192.168.10.14; SERVICE-NETWORK2=192.168.20.5, 192.168.20.14; tmo-autovnf2-uas-orchestration=172.18.180.14; DI-INTERNAL2=192.168.2.7; DI-INTERNAL1=192.168.1.5 |
| b283d43c-6e0c-42e8-87d4-a3af15a61a83 | vnfd1-deployment_s5_0_672bbb00-34f2-46e7-a756-52907e1d3b3d | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.21, 192.168.10.24; SERVICE-NETWORK2=192.168.20.21, 192.168.20.24; tmo-autovnf2-uas-orchestration=172.18.180.20; DI-INTERNAL2=192.168.2.13; DI-INTERNAL1=192.168.1.16 |
| 637547ad-094e-4132-8613-b4d8502ec385 | vnfd1-deployment_s6_0_23cc139b-a7ca-45fb-b005-733c98ccc299 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.13, 192.168.10.19; SERVICE-NETWORK2=192.168.20.9, 192.168.20.22; tmo-autovnf2-uas-orchestration=172.18.180.16; DI-INTERNAL2=192.168.2.19; DI-INTERNAL1=192.168.1.21 |
| 4169438f-6a24-4357-ad39-2a35671d29e1 | vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.6; tmo-autovnf2-uas-management=172.18.181.8 |
| 30431294-c3bb-43e6-9bb3-6b377aefbc3d | vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.7; tmo-autovnf2-uas-management=172.18.181.9 |
| 28ab33d5-7e08-45fe-8a27-dfb68cf50321 | vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.3; tmo-autovnf2-uas-management=172.18.181.7 |
Pare um dos EM do ESC e verifique se ele entrou no ESTADO SHUTOFF.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_INERT_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_SHUTOFF_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Agora, depois que o EM entrar no ESTADO DE ENVIO, reinicialize o outro EM do OSPD (OpenStack Platform Diretor).
[stack@director ~]$ nova reboot --hard vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a
Request to reboot server <Server: vnfd2-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a> has been accepted.
Faça login no VIP EM novamente e verifique o status do HA.
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
Se o HA estiver no estado "mestre", inicie o EM que foi desligado mais cedo do ESC. Caso contrário, reinicialize o próximo EM do OSPD e verifique o status do HA novamente.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action START vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_ALIVE_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Depois de iniciar o EM a partir do ESC, verifique o status HA do EM. Deveria ter sido restaurado.
admin@scm# em-ha-status
ha-status MASTER
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 4-1516609103
ncs-state ha connected-slave [ 2-1516609363 ]
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
4 up up up
Colaborado por engenheiros da Cisco
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)