Restauration haute disponibilité dans le cluster Ultra-M Element Manager - vEPC
Options de téléchargement
-
ePub (278.0 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (251.1 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit les étapes requises pour restaurer la haute disponibilité (HA) dans le cluster Element Manager (EM) d'une configuration Ultra-M qui héberge les fonctions de réseau virtuel (VNF) de StarOS.
Informations générales
Ultra-M est une solution de coeur de réseau de paquets mobiles virtualisés prépackagée et validée conçue pour simplifier le déploiement des VNF. La solution Ultra-M se compose des types de machines virtuelles mentionnés :
- IT automatique
- Déploiement automatique
- Ultra Automation Services (UAS)
- Gestionnaire d'éléments (EM)
- Contrôleur de services élastiques (ESC)
- Fonction de contrôle (CF)
- Fonction de session (SF)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont représentés dans cette image :
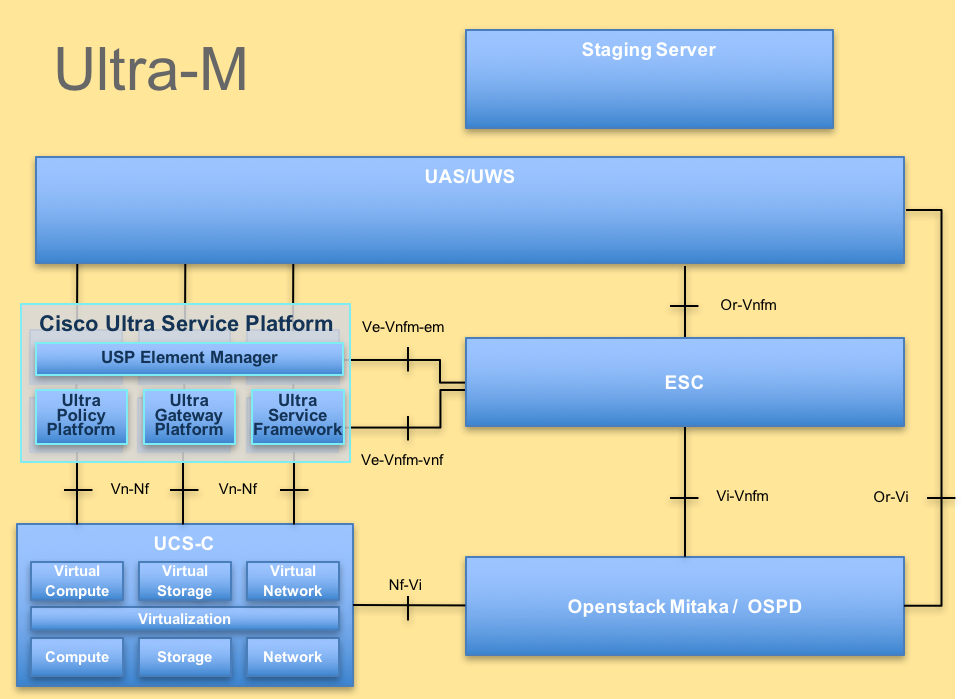 Architecture UltraM
Architecture UltraM
Ce document est destiné au personnel Cisco qui connaît la plate-forme Cisco Ultra-M.
Note: La version Ultra M 5.1.x est prise en compte afin de définir les procédures de ce document.
Abréviations
| HA | Haute disponibilité |
| VNF | Fonction de réseau virtuel |
| FC | Fonction de contrôle |
| SF | Fonction de service |
| Échap | Contrôleur de service flexible |
| MOP | Méthode de procédure |
| OSD | Disques de stockage d'objets |
| HDD | Disque dur |
| SSD | Disque dur SSD |
| VIM | Gestionnaire d'infrastructure virtuelle |
| VM | Machine virtuelle |
| EM | Gestionnaire d'éléments |
| UAS | Services d’automatisation ultra |
| UUID | Identificateur unique |
Flux de travail du MoP
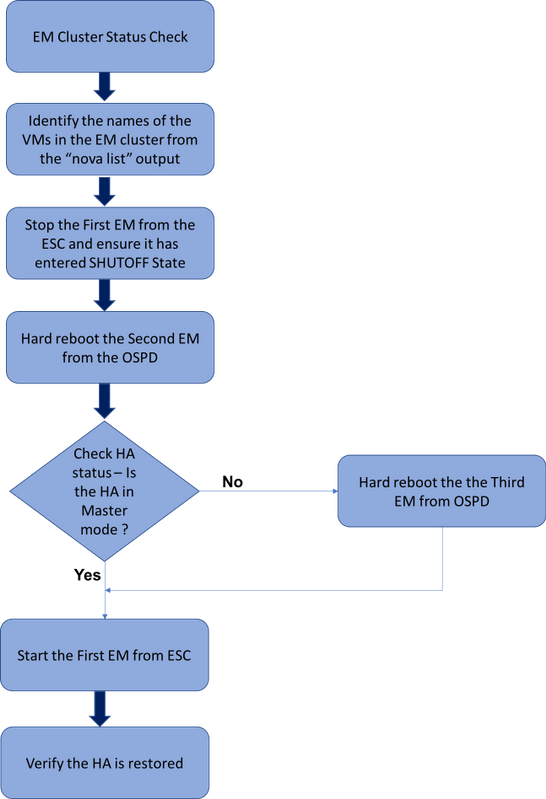 Workflow de haut niveau de la procédure de restauration EM HA
Workflow de haut niveau de la procédure de restauration EM HA
Vérifier l'état du cluster
Connectez-vous au module EM actif et vérifiez l'état de la haute disponibilité. Il peut y avoir deux scénarios :
1. Le mode HA n'est pas :
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode none
admin@scm# show ems
%no entries found%
2. Le cluster EM n'a qu'un noeud (le cluster EM se compose de 3 machines virtuelles) :
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
----------------------
2 up down down
Dans les deux cas, l'état HA peut être restauré par les étapes mentionnées dans la section suivante.
Procédure de restauration HA
Identifiez les noms des machines virtuelles des EM qui font partie du cluster dans la liste nova. Trois machines virtuelles font partie d'un cluster EM.
[stack@director ~]$ nova list | grep vnfd1
| e75ae5ee-2236-4ffd-a0d4-054ec246d506 | vnfd1-deployment_c1_0_13d5f181-0bd3-43e4-be2d-ada02636d870 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.22; DI-INTERNAL2=192.168.2.17; DI-INTERNAL1=192.168.1.14; tmo-autovnf2-uas-management=172.18.181.23 |
| 33c779d2-e271-47af-8ad5-6a982c79ba62 | vnfd1-deployment_c4_0_9dd6e15b-8f72-43e7-94c0-924191d99555 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.13; DI-INTERNAL2=192.168.2.14; DI-INTERNAL1=192.168.1.4; tmo-autovnf2-uas-management=172.18.181.21 |
| 65344d53-de09-4b0b-89a6-85d5cfdb3a55 | vnfd1-deployment_s2_0_b2cbf15a-3107-45c7-8edf-1afc5b787132 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.4, 192.168.10.9; SERVICE-NETWORK2=192.168.20.17, 192.168.20.6; tmo-autovnf2-uas-orchestration=172.18.180.12; DI-INTERNAL2=192.168.2.6; DI-INTERNAL1=192.168.1.12 |
| e1a6762d-4e84-4a86-a1b1-84772b3368dc | vnfd1-deployment_s3_0_882cf1ed-fe7a-47a7-b833-dd3e284b3038 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.22, 192.168.10.14; SERVICE-NETWORK2=192.168.20.5, 192.168.20.14; tmo-autovnf2-uas-orchestration=172.18.180.14; DI-INTERNAL2=192.168.2.7; DI-INTERNAL1=192.168.1.5 |
| b283d43c-6e0c-42e8-87d4-a3af15a61a83 | vnfd1-deployment_s5_0_672bbb00-34f2-46e7-a756-52907e1d3b3d | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.21, 192.168.10.24; SERVICE-NETWORK2=192.168.20.21, 192.168.20.24; tmo-autovnf2-uas-orchestration=172.18.180.20; DI-INTERNAL2=192.168.2.13; DI-INTERNAL1=192.168.1.16 |
| 637547ad-094e-4132-8613-b4d8502ec385 | vnfd1-deployment_s6_0_23cc139b-a7ca-45fb-b005-733c98ccc299 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.13, 192.168.10.19; SERVICE-NETWORK2=192.168.20.9, 192.168.20.22; tmo-autovnf2-uas-orchestration=172.18.180.16; DI-INTERNAL2=192.168.2.19; DI-INTERNAL1=192.168.1.21 |
| 4169438f-6a24-4357-ad39-2a35671d29e1 | vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.6; tmo-autovnf2-uas-management=172.18.181.8 |
| 30431294-c3bb-43e6-9bb3-6b377aefbc3d | vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.7; tmo-autovnf2-uas-management=172.18.181.9 |
| 28ab33d5-7e08-45fe-8a27-dfb68cf50321 | vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.3; tmo-autovnf2-uas-management=172.18.181.7 |
Arrêtez l'un des EM de l'ESC et vérifiez s'il est entré dans l'ÉTAT SHUTOFF.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_INERT_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_SHUTOFF_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Maintenant, une fois que le module EM est entré dans l'ÉTAT SHUTOFF, redémarrez l'autre module EM à partir de l'OSPD (OpenStack Platform Director).
[stack@director ~]$ nova reboot --hard vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a
Request to reboot server <Server: vnfd2-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a> has been accepted.
Connectez-vous à nouveau au processeur VIP EM et vérifiez l'état de la haute disponibilité.
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
Si la HA est en état « maître », démarrez le module EM qui était précédemment Shutoff de l'ESC. Sinon, redémarrez le prochain module EM à partir d'OSPD, puis vérifiez à nouveau l'état HA.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action START vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_ALIVE_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Après avoir démarré le module EM à partir de l'ESC, vérifiez l'état HA du module EM. Elle aurait dû être restaurée.
admin@scm# em-ha-status
ha-status MASTER
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 4-1516609103
ncs-state ha connected-slave [ 2-1516609363 ]
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
4 up up up
Contribution d’experts de Cisco
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)