Restauración de alta disponibilidad en clúster de gestor de elementos Ultra-M - vEPC
Opciones de descarga
-
ePub (278.5 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (251.8 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para restaurar la alta disponibilidad (HA) en el clúster de Element Manager (EM) de una configuración Ultra-M que aloja las funciones de red virtual (VNF) de StarOS.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizada validada y empaquetada previamente diseñada para simplificar la implementación de VNF. La solución Ultra-M consta de los tipos de máquina virtual (VM) mencionados:
- TI automática
- Implementación automática
- Servicios de automatización (UAS)
- Administrador de elementos (EM)
- Controlador de servicios elásticos (ESC)
- Función de control (CF)
- Función de sesión (SF)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados se ilustran en esta imagen:
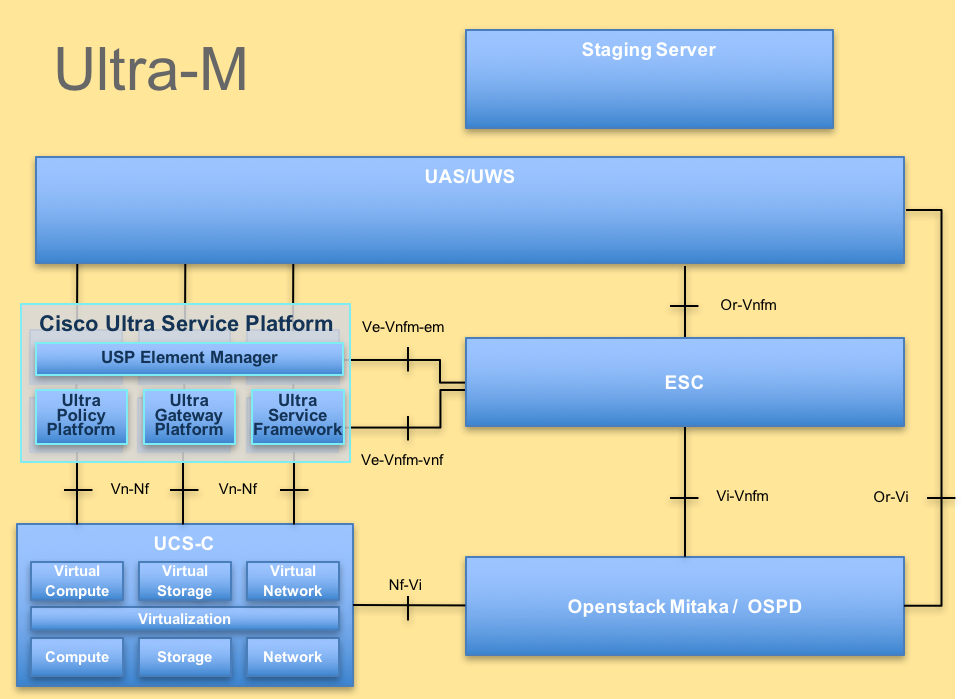 Arquitectura UltraM
Arquitectura UltraM
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Cisco Ultra-M.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| HA | Alta disponibilidad |
| VNF | Función de red virtual |
| CF | Función de control |
| SF | Función de servicio |
| ESC | Controlador de servicio elástico |
| MOP | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| HDD | Unidad de disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
Flujo de trabajo del MoP
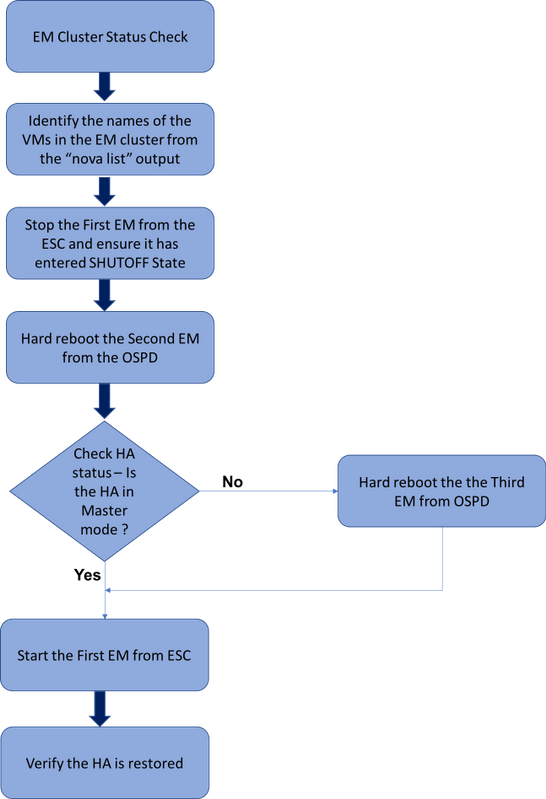 Flujo de trabajo de alto nivel del procedimiento de restauración EM HA
Flujo de trabajo de alto nivel del procedimiento de restauración EM HA
Comprobar estado del clúster
Inicie sesión en el EM activo y verifique el estado HA. Puede haber dos escenarios:
1. El modo HA no es ninguno:
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode none
admin@scm# show ems
%no entries found%
2. El clúster de EM solo tiene un nodo (el clúster de EM consta de 3 VM):
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
----------------------
2 up down down
En ambos casos, el estado HA se puede restaurar mediante los pasos mencionados en la siguiente sección.
Procedimiento de restauración HA
Identifique los nombres de VM de EM que forman parte del clúster de la lista nova. Habrá tres VM que forman parte de un clúster de EM.
[stack@director ~]$ nova list | grep vnfd1
| e75ae5ee-2236-4ffd-a0d4-054ec246d506 | vnfd1-deployment_c1_0_13d5f181-0bd3-43e4-be2d-ada02636d870 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.22; DI-INTERNAL2=192.168.2.17; DI-INTERNAL1=192.168.1.14; tmo-autovnf2-uas-management=172.18.181.23 |
| 33c779d2-e271-47af-8ad5-6a982c79ba62 | vnfd1-deployment_c4_0_9dd6e15b-8f72-43e7-94c0-924191d99555 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.13; DI-INTERNAL2=192.168.2.14; DI-INTERNAL1=192.168.1.4; tmo-autovnf2-uas-management=172.18.181.21 |
| 65344d53-de09-4b0b-89a6-85d5cfdb3a55 | vnfd1-deployment_s2_0_b2cbf15a-3107-45c7-8edf-1afc5b787132 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.4, 192.168.10.9; SERVICE-NETWORK2=192.168.20.17, 192.168.20.6; tmo-autovnf2-uas-orchestration=172.18.180.12; DI-INTERNAL2=192.168.2.6; DI-INTERNAL1=192.168.1.12 |
| e1a6762d-4e84-4a86-a1b1-84772b3368dc | vnfd1-deployment_s3_0_882cf1ed-fe7a-47a7-b833-dd3e284b3038 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.22, 192.168.10.14; SERVICE-NETWORK2=192.168.20.5, 192.168.20.14; tmo-autovnf2-uas-orchestration=172.18.180.14; DI-INTERNAL2=192.168.2.7; DI-INTERNAL1=192.168.1.5 |
| b283d43c-6e0c-42e8-87d4-a3af15a61a83 | vnfd1-deployment_s5_0_672bbb00-34f2-46e7-a756-52907e1d3b3d | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.21, 192.168.10.24; SERVICE-NETWORK2=192.168.20.21, 192.168.20.24; tmo-autovnf2-uas-orchestration=172.18.180.20; DI-INTERNAL2=192.168.2.13; DI-INTERNAL1=192.168.1.16 |
| 637547ad-094e-4132-8613-b4d8502ec385 | vnfd1-deployment_s6_0_23cc139b-a7ca-45fb-b005-733c98ccc299 | ACTIVE | - | Running | SERVICE-NETWORK1=192.168.10.13, 192.168.10.19; SERVICE-NETWORK2=192.168.20.9, 192.168.20.22; tmo-autovnf2-uas-orchestration=172.18.180.16; DI-INTERNAL2=192.168.2.19; DI-INTERNAL1=192.168.1.21 |
| 4169438f-6a24-4357-ad39-2a35671d29e1 | vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.6; tmo-autovnf2-uas-management=172.18.181.8 |
| 30431294-c3bb-43e6-9bb3-6b377aefbc3d | vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.7; tmo-autovnf2-uas-management=172.18.181.9 |
| 28ab33d5-7e08-45fe-8a27-dfb68cf50321 | vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0 | ACTIVE | - | Running | tmo-autovnf2-uas-orchestration=172.18.180.3; tmo-autovnf2-uas-management=172.18.181.7 |
Detenga uno de los EM del ESC y verifique si ha ingresado al ESTADO SHUTOFF.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_INERT_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_SHUTOFF_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Ahora, una vez que EM ha ingresado el estado SHUTOFF, reinicie el otro EM desde OpenStack Platform Director (OSPD).
[stack@director ~]$ nova reboot --hard vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a
Request to reboot server <Server: vnfd2-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a> has been accepted.
Vuelva a iniciar sesión en EM VIP y verifique el estado HA.
ubuntu@vnfd1deploymentem-0:~$ ncs_cli -u admin -C
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 2-1528893823
Si el HA se encuentra en estado "maestro", inicie el EM que se cerró anteriormente desde ESC. De lo contrario, proceda a reiniciar el siguiente EM desde OSPD y luego verifique el estado HA nuevamente.
[admin@vnfm1-esc-0 esc-cli]$ /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action START vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
[admin@vnfm1-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
vnfd1-deployment_vnfd1-_0_02d1510d-53dd-4a14-9e21-b3b367fef5b8
VM_ALIVE_STATE
<vm_name>vnfd1-deployment_vnfd1-_0_f17989e3-302a-4681-be46-f2ebf62b252a</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>vnfd1-deployment_vnfd1-_0_f63241f3-2516-4fc4-92f3-06e45054dba0</vm_name>
<state>VM_ALIVE_STATE</state>
Después de iniciar el EM desde ESC, verifique el estado HA de EM. Debería haberse restablecido.
admin@scm# em-ha-status
ha-status MASTER
admin@scm# show ncs-state ha
ncs-state ha mode master
ncs-state ha node-id 4-1516609103
ncs-state ha connected-slave [ 2-1516609363 ]
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
4 up up up
Con la colaboración de ingenieros de Cisco
- Padmaraj RamanoudjamCisco Advanced Services
- Partheeban RajagopalCisco Advanced Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)